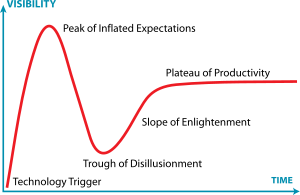
Hadoop has passed the hype cycle & is stable now. Now Hadoop is with Plateau of Productivity.
My notes here on hadoop should make readers hadoop buzz words compliant & give better idea of over-all picture.
What is Hadoop?
A cost-effective, scalable, distributed and flexible big data processing framework written in java based on Map-Reduce algorithm. MapReduce is a algorithm proposed by Google that breaks complex tasks down into smaller elements which can be executed in parallel.
Hadoop at core consists of two parts, one a special file system called Hadoop Distributed File System (HDFS) and Map-Reduce Framework that defines two phases to process the data a map and reduce.
Hadoop at core consists of two parts, one a special file system called Hadoop Distributed File System (HDFS) and Map-Reduce Framework that defines two phases to process the data a map and reduce.
Why Hadoop?
Traditional storage with RDBMS is costly and unsuitable in follwing scenarios
- Too much of data that too in unstructured format (100s of Terabytes, Peta bytes)
- Large # of applications to use a single filesystem namespace in distributed execution space
- In-expensive storage of large data, but can be still easily queried.
- Big data with high volume & velocity
Relational databases are designed with good principles of data durability, isolation and independence but the design is centralized and tends to get disk IO bound for high write workloads. The use of locking at different levels (row, page, table level) for consistency/isolation and the need to flush transaction state to disk introduces scalability challenges requiring users to scale by deploying heavy machines (vertical scaling).
Many tech vendors like EMC,Y!, Twitter, IBM,Amazon,Oracle & even Microsoft has got Hadoop-oriented "big data" strategy. Hadoop has proven to work with many of the big companies & huge investment in hadoop and its related technology made by them makes it viable option for handling big data in years to come.
Hadoop Use Cases:
Many tech vendors like EMC,Y!, Twitter, IBM,Amazon,Oracle & even Microsoft has got Hadoop-oriented "big data" strategy. Hadoop has proven to work with many of the big companies & huge investment in hadoop and its related technology made by them makes it viable option for handling big data in years to come.
Hadoop Use Cases:
This wiki-page lists out 100s of companies and their usages alphabetically,
Here is the list that I picked from there.
- Log files processing,
- Machine learning
- User experience optimization/Prediction of behaviours based on the patterns and build the recommender system for behavioral targeting with pattern discovery/analysis.
- Billions of lines of GPS data to create TrafficSpeeds for accurate traffic speed forecast
(proximity operators, hub and spoke search terms, customized relevance ranking, stemming, white and black lists, Data mining, Analytics and machine learning) Data from various wide verity of sources Ex: sensors, cameras, feeds,streaming, logs, user interactions
Where Hadoop doesn't make sense
You cannot directly use Hadoop as a substitute for a database that takes query & returns result in milliseconds, so if there is requirement to have sub-second interactive reporting from your data, or using the data in multi-step, updates/insertions, complex transactions, an RDBMS solution may still be your best bet.
By design Hadoop is suited for batch index building,and is not proper for incremental index building and search.
Hadoop eco system
There are software add on components developed on hadoop to make life simpler, VMWare recently announced that Spring also will have support for Hadoop under their "Spring Data" umbrella.
- HBase - Column-store database (of the order of terabytes) based on Google's big table
- Pig - Yahoo owned DSL for Data-flow or routing data
- Hive - Facebook owned DSL for routing data but based on SQL
- ZooKeeper - Distributed consensus engine with concurrent access
All the big companies (Twitter,Amazon, Yahoo, Facebook) have something to offer over the Hadoop which is a good thing.
Hadoop Core components:
At core hadoop can be grouped into following
- HDFS - Hadoop Distributed File System, is responsible for storing huge data on the cluster.
- Hadoop Daemons - A set of services offering to work with the data.
- Hadoop HDFS API - APIs to communicate with the various nodes (services) from applications.
Here is brief write up on each of the components:
HDFS:
This is a distributed file system designed to run on commodity(low cost) hardware & highly fault tolerent.
It provides the high throughput with large data sets (files). HDFS supports write-once-read-many semantics on files
In HDFS data is split into blocks and distributed across multiple nodes in the cluster. Each block is typically 64Mb or 128Mb in size.
HDFS Vs NAS
In HDFS Data Blocks are distributed across local drives of all machines in a cluster. Whereas in NAS data is stored on dedicated hardware.
HDFS is designed to work with MapReduce System, since computation are moved to data. NAS is not suitable for MapReduce since data is stored seperately from the computations.
HDFS runs on a cluster of machines and provides redundancy using a replication protocal. Whereas NAS is provided by a single machine therefore does not provide data redundancy.
Hadoop Daemon services or modules:
Hadoop Daemon services or modules:
Hadoop is comprised of five separate daemons. Each of these daemon run in its own JVM.
Master nodes:
- NameNode - This daemon stores and maintains the metadata for HDFS.
- Secondary NameNode - Performs housekeeping functions for the NameNode.
- JobTracker - Manages MapReduce jobs, distributes individual tasks to machines running the Task Tracker.
Slave nodes
- DataNode – Stores actual HDFS data blocks.
- TaskTracker - Responsible for instantiating and monitoring individual Map and Reduce tasks.
NameNode :
NameNode is heart of HDFS file system. It keeps the directory hierachy information of all files in the file system, and tracks where across the cluster the file data is kept. It does not store the data of these files itself but just metadata. "NameNode" is a Single Point of Failure for the HDFS Cluster & makes all decisions regarding replication of blocks.Any hadoop user applications will have to talk to NameNode through Hadoop HDFS API to locate a file or to add/copy/move/delete a file.
Data Node :
A DataNode stores data in the Hadoop File System HDFS. DataNode instances can talk to each other, this is mostly during replicating data.
JobTracker :
A daemon service for submitting and tracking jobs(a processing unit) in Hadoop & is single point of failure for the Hadoop MapReduce service.
As per wiki:
Client applications submit jobs to the Job tracker.
The JobTracker talks to the NameNode to determine the location of the data
The JobTracker talks to the NameNode to determine the location of the data
The JobTracker locates TaskTracker nodes with available slots at or near the data
The JobTracker submits the work to the chosen TaskTracker nodes.
The TaskTracker nodes are monitored. If they do not submit heartbeat signals often enough, they are deemed to have failed and the work is scheduled on a different TaskTracker.
A TaskTracker will notify the JobTracker when a task fails. The JobTracker decides what to do then: it may resubmit the job elsewhere, it may mark that specific record as something to avoid, and it may may even blacklist the TaskTracker as unreliable.
When the work is completed, the JobTracker updates its status.
Client applications can poll the JobTracker for information.
Client applications can poll the JobTracker for information.
Task Tracker:
Task Tracker is a slave node daemon in the cluster that accepts tasks (Map, Reduce and Shuffle operations) & monitors these task instances(Task instances are the actual MapReduce jobs), from a JobTracker.
Miscellaneous:
MapReduce programming model does not allow reducers to communicate with each other. Reducers run in isolation & hence can be zero as well.
Combiners are used to increase the efficiency of a MapReduce program. They are used to aggregate intermediate map output locally on individual mapper outputs. Combiners can help you reduce the amount of data that needs to be transferred across to the reducers.
Speculative execution is a way of coping with individual Machine performance.
Some Criticisms:
"Hadoop brings a tons of data, but until you know what to ask about it, it’s pretty much garbage in, garbage out." - There are limited use cases for this especially for generic programmer to fully invest on this.
"Does querying huge data sets win over the advanced algorithms applied over limited data" - I am skeptical about querying huge data
"While most of Hadoop is built using Java, a larger and growing portion is being rewritten in C and C++" - I thought Google Map-Reduce must be better & converting some components to C++ is not a good sign for Java
"Configuration parameters are pretty huge" - that's a design smell I guess it shouldn't that complex.

